题目:Towards Face Encryption by Generating Adversarial Identity Masks
作者:Xiao Yang, Yinpeng Dong, Tianyu Pang, Hang Su, Jun Zhu, Yuefeng Chen, Hui Xue
链接:文章链接
代码链接:代码链接
1 摘要翻译
随着数以亿计的个人数据通过社交媒体和网络共享,数据的隐私和安全问题越来越受到关注。为了减少面部照片泄露身份信息的情况,已作出了一些尝试,例如利用图像模糊处理技术。然而,目前的大多数结果不是对可感知性不满意,就是对人脸识别系统攻击低效。我们在本文中的目标是开发一种技术,可以加密个人照片,这样它们可以保护用户不受未经授权的人脸识别系统的影响,但在视觉上仍然与人类的原始版本相同。为此,我们提出了一种有针对性的身份保护迭代方法target identity-protection iterative method(TIP-IM)来生成对抗性的身份面具,该面具可以叠加在人脸图像上,这样就可以在不牺牲视觉质量的情况下隐藏身份。大量实验表明,在实际测试场景下,TIP-IM对各种最先进的人脸识别模型提供了95%以上的保护成功率。此外,我们还展示了我们的方法在一个商业API服务上的实际和有效的适用性。
基本问题
- 论文解决的问题:为人脸图像生成不可感知的、有效的隐私保护掩码。
2 Introduction
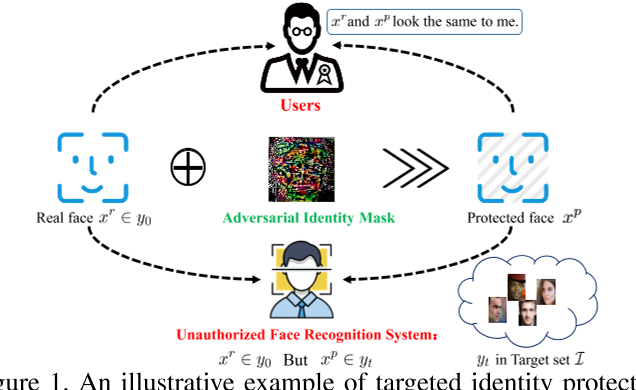
社交媒体和网络的蓬勃发展带来了大量的个人数据(如照片)被公开分享。随着深度神经网络的日益普及,这些技术极大地提高了人脸识别系统处理个人数据的能力,但作为副产品,也增加了个人信息隐私泄露的潜在风险。例如,未经授权的第三方可能会在未经许可的情况下抓取和识别社交媒体(如Twitter, Facebook, LinkedIn等)上共享的照片。因此,在不影响用户体验的前提下,为用户提供一种有效的方式来保护其隐私信息不被未经授权的系统识别和泄露是必要的。(提出人脸隐私保护的必要性)
过去的几年见证了人脸加密在安全和计算机视觉领域的进步。在现有的技术中,基于模糊的方法得到了广泛的研究。传统的模糊处理技术,如模糊化、像素化、暗化和遮挡,可能在可感知性上令人满意或能有效地对抗识别系统。生成对抗网络(GANs)的最新进展为生成更真实的图像进行模糊处理提供了一种很有吸引力的方法。但由于对某些有判别力的特征进行了夸张和抑制,得到的模糊图像在视觉外观上与原始图像有显著差异,偶尔会产生带有伪影的不自然的输出图像。(用模糊方法进行人脸加密)
最近的研究发现,对抗样本通过在原始图像上叠加对抗性扰动,可以逃避FR系统的识别。它成为了一种很有吸引力的方式来应用对抗扰动来隐藏一个人的身份,即使是在更严格的限制下模仿一些被授权的或生成的人脸图像(例如,由社交媒体服务提供)。它提供了一种可能的解决方案来指定输出,这可能会避免侵犯他人的隐私(图像被识别为任意身份)。尽管如此,应该注意到,尽管现有方法(如PGD和MIM)产生的对抗扰动的强度变化很小(如[0,255]中每个像素的强度变化为12或16),但由于Fig.2所示的伪影,它们仍然可能牺牲视觉质量,并且有研究指出,ℓp-范数限制的对抗扰动不能很好地适应人类感知。此外,目前的对抗攻击主要依赖于目标系统的白盒模型或大量的模型查询,这在现实场景中(如社交媒体上的未经授权的人脸识别系统)难以实现身份保护。(用对抗样本进行人脸加密及不足)
在本文中,我们从普通用户的角度考虑了一些有价值的问题,并提出了缓解真实社交媒体中个人照片身份泄露的建议。我们特别关注face identification,这是人脸识别中一个典型的子任务,其目标是在一个未知的gallery identity set中识别真实的人脸图像,我们的目标是将真实的人脸图像识别为一个unknown gallery identity set,因为它可以被未经授权的应用程序用于识别用户的身份信息。如Fig.1所示,人脸加密是为了阻止恶意应用程序的自动推理能力,使其预测服务提供商错误的被授权的授权或虚拟目标。一般来说,人们对人脸识别系统不可知,不可能直接访问查询。因此,我们需要针对代理模型生成对抗掩码,以欺骗黑盒人脸识别系统。此外,当用户在社交媒体上分享受保护的照片时,我们尽量不影响用户体验,同时对未经授权的识别系统隐藏其身份。因此,受保护的图像在视觉上也应该像相应的原始图像一样然,否则可能会引入不希望看到的伪影。(本文提出的方法的一些考虑,target set,黑盒,自然)
为了解决上述挑战,我们提出了targeted identity-protection iterative method(TIP-IM)来对黑盒人脸识别系统进行人脸加密。提出的方法生成可迁移的且不可察觉的对抗身份掩码。好的可迁移性意味着一个模型可以有效地欺骗其他黑盒人脸识别系统,同时不可感知性意味着一张由对抗身份掩码处理的照片在视觉上对人类来说是自然的。具体来说,为了确保生成的图像不会被任意误分类为其他身份,我们从互联网上收集的数据集中随机选择一组人脸图像作为我们实验中指定的目标。该方法通过一种新颖的迭代优化算法,在多目标识别的白盒和黑盒人脸系统中获得了较好的性能。(本文提出方法的具体内容,可迁移,不可感知,多目标)
在实际和具有挑战性的open-set测试场景下进行的大量实验表明,我们的算法对白盒人脸系统提供了95%以上的保护成功率,并且即使与各种最先进的算法相比,也比以前的方法有一定的优势。此外,我们还通过考虑一个商业API服务,在一个真实世界的实验中证明了它的有效性。我们的主要贡献总结如下:
- 从用户的角度出发,我们涉及到一些有价值的考虑,以保护隐私免受未经授权的身份识别系统的侵害,包括target protection、natural output、black-box system和unknown gallery set。
- 我们提出了targeted identity-protection iterative method(TIP-IM)来生成对抗身份掩码,该方法考虑了多目标集,并引入了一种新的优化机制来保证在不同场景下的有效性。

3 Adversarial Identity Mask
用\(f(\mathbf{x} ):\chi \to \mathcal{R}^d\) 表示一个人脸识别系统,对一个人脸图像\(\mathbf{x}\in \mathcal{X}\subset \mathcal{R}^n\)提取在\(\mathcal{R}^d\)内固定长度的特征表示。给定度量\(\mathcal{D}_f(\mathbf{x}_1, \mathbf{x}_2)=||f(\mathbf{x}_1)-f(\mathbf{x}_2)||_2^2\)来描述两张人脸图像的特征距离。人脸识别是识别一个probe图像和一个人脸图像集合\(\mathcal{G}=\{\mathbf{x}_1^g, \dots,\mathbf{x}_m^g\}\),并返回其中与probe图像特征距离最近的图像的身份。
在本文中,我们从用户的角度考虑了一些有价值的因素,以保护用户的照片不受非法人脸识别系统的影响。具体来说,为了隐藏用户图像\(\mathbf{x}^r\)的真实身份\(y\),我们通过在\(\mathbf{x}^r\)上添加一个对抗性身份掩码\(\mathbf{m}^a\)来生成一个被保护的图像\(\mathbf{x}^p\),可以表示为\(\mathbf{x}^p=\mathbf{x}^r+\mathbf{m}^a\),来使人脸识别系统将\(\mathbf{x}^p\)识别为不同的被授权的身份或者生成图像对应的虚拟的身份。与指定一个目标身份来生成保护图像不同,我们选择一个身份集合\(\mathcal{T}=\{y_1, \dots, y_k\}\),我们使人人脸识别系统将被保护图像识别为\(\mathcal{T}\)中的任意一个目标身份,这样可以使身份保护更容易实现。
正式的说,使\(\mathcal{G}_y=\{x|x\in \mathcal{G}, \mathcal{O}(\mathbf{x})=y\}\)表示包含\(\mathcal{G}\)中所有属于\(\mathbf{x}^r\)的真实身份\(y\)的所有人脸图像的集合,其中\(\mathcal{O}\)的作用是给出图像的ground-truth,并且\(\mathcal{G}_\mathcal{T}=\cup _{q\le i \le k} \mathcal{G}_{y_i}\)表示gallery set \(\mathcal{G}\)中包含的所有属于\(\mathcal{T}\)的目标身份的图像的集合。为了隐藏\(\mathbf{x}^r\)的身份,生成的保护图像\(\mathbf{x}^p\)要满足约束 \[ \exists \mathbf{x}^t\in \mathcal{G}_\mathcal{T}, \forall \mathbf{x}\in \mathcal{G}_y:\mathcal{D}_f(\mathbf{x}^p, \mathbf{x})>\mathcal{D}_f(\mathbf{x}^p, \mathbf{x}^t) \,\,\,\,\,\,(1) \] 与之前研究的设定相比,我们从一般用户的角度考虑了更多的实际问题,主要体现在以下三个方面:
Naturalness
为了使被保护图像与原始图像难以区分,通常的做法是限制保护图像与原始图像之间的ℓp (p = 2,∞等)范数。然而,ℓp范数下的扰动不能自然地很好地拟合人类的感知。因此,我们要求受保护图像除了ℓp范数界的约束外,还要看起来自然,使其约束于真实图像的数据流形,从而达到人眼无法察觉的效果。我们使用一个目标函数来提高被保护图像的自然度。
Unawareness of gallery set
对于一个真实的人脸识别系统,我们不知道它的gallery set \(\mathcal{G}\),这也表明不可能直接求解上式(1),而以前的工作假设gallery set可以访问或者是closed-set设定。为了解决这个问题,我们使用替代人脸图像进行优化。具体的,我们收集图像集\(\tilde{\mathcal{G}_\mathcal{T}}\),包含目标身份\(\mathcal{T}\)的人脸图像作为 \(\mathcal{G}_\mathcal{T}\)的替代,并且使用\(\{\mathbf{x}^r\}\)而不是\(\mathcal{G}_y\)。使用替代图像的合理性在于,一个身份的人脸表征是相似的,因此优化后的与替代图像相似的受保护图像的表征也可以接近gallery set中属于相同目标身份的图像。
Unknown face system
在实践中,我们也不知道人脸识别模型,包括它的架构、参数和梯度。以前的方法依赖于对目标模型的白盒访问,这在真实的身份保护场景中是不切实际的。因此,我们采用代理白盒模型来生成受保护的图像,以提高对抗式掩码对未知人脸系统的可迁移性。
4 Methodology
4.1 Problem Formulation
将目标隐私保护函数定义为:
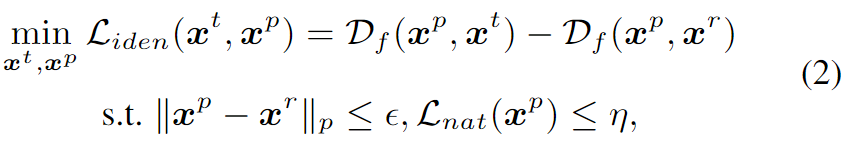
其中,\(\mathbf{x}^t\in \tilde{\mathcal{G}_\mathcal{T}}\),并且\(\mathcal{L}_{iden}\) 是一个相对的识别损失,是生成的\(\mathbf{x}^p\)在特征空间上增加与\(\mathbf{x}^r\)的距离,缩小与\(\mathbf{x}^t\)的距离。$_{nat}$ 是使\(\mathbf{x}^p\)看起来自然的限制条件。同时也限制了\(l_p\,\,norm\)。
本文中使用maximum mean discrepancy(MMD) 作为\(\mathcal{L}_{nat}\),因为它是一种有效的非参数和可微的度量,能够比较两个数据分布和评估生成的图像的不可感知性。即给定两个数据集合\(\mathbf{X}^p=\{\mathbf{x}_1^p, \dots, \mathbf{x}_2^p\}\) 和 \(\mathbf{X}^r=\{\mathbf{x}_1^r, \dots, \mathbf{x}_2^r\}\),由N个生成的图像和N个真实的图像组成,MMD通过下式算两个分布的差异:
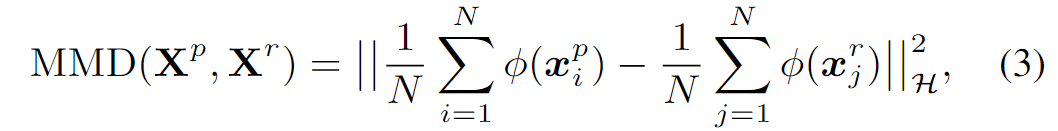
其中\(\phi(·)\)将数据映射到再生核希尔伯特空间中(RKHS)。
通过最小化生成分布的样本\(\mathbf{X}^p\)和真实数据分布的样本\(\mathbf{X}^r\)之间的MMD,我们可以将\(\mathbf{X}^p\)约束在真实数据分布的流形上,这意味着\(\mathbf{X}^p\)中被保护的图像将像真实的图像一样自然。
由于MMD是一种可微的度量,并且定义在batch上,因此我们将MMD集成到Eq.(2)中,并用batch-based的公式重写目标为:
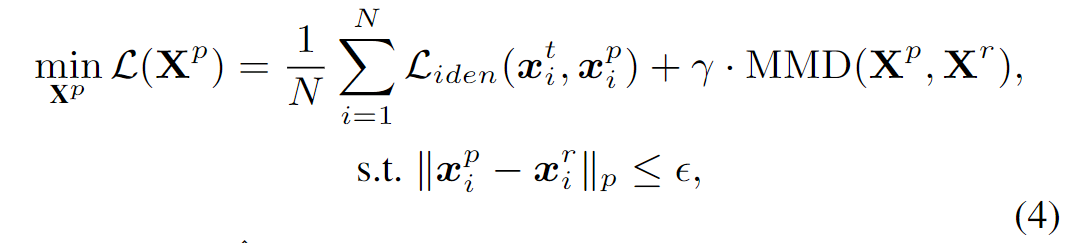
其中,\(\mathbf{x}_i^t\in \tilde{\mathcal{G}_\mathcal{T}}\),是\(\mathbf{x}_i^t\)对应的那个目标图像, 并且\(\gamma\)是平衡两个loss的超参数。
4.2 Target Identity-Protection Iterative Method
上一节给定了\(\mathcal{L}(\mathbf{X}^p)\)的表达式,所以通过最小化\(\mathcal{L}(\mathbf{X}^p)\)即可生成一个batch被保护图像\(\mathbf{X}^p\)。并且通过fast gradient方法做多次迭代,最小化\(\mathcal{L}(\mathbf{X}^p)\)。即通过下式生成:
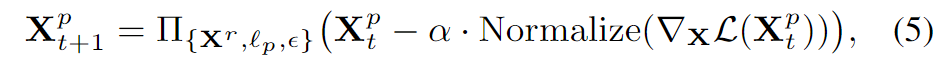
其中\(\mathbf{X}^p_t\)是迭代了t次的被保护图像,\(\Pi\)是投影函数,将图像投影到\(l_p\)范数边界, Normalize是用来归一化梯度的(如在无穷范数中的符号函数,在l2范数中的l2归一化)。共进行\(T\)次迭代。
为了防止受保护图像陷入局部极小值,并提高其对其他黑箱人脸识别模型的可迁移性,我们将动量技术引入迭代过程。
4.3 Search Optimal \(x^t\) via Greedy Insertion
下面的问题就是,如果\(\tilde{\mathcal{G}_\mathcal{T}}\)中不只有一张目标图片,那么就为获得更好的性能提供了更多潜在的优化方向。因此,本文开发了一种优化算法,在生成受保护图像的同时搜索最优目标。具体来说,对于式(5)中\(T\)次迭代的迭代过程,我们在\(\tilde{\mathcal{G}_\mathcal{T}}\)中为每一个受保护图像每次迭代选择一个代表目标进行更新,这属于子集选择问题。
定义. \(S_t\)表示每次迭代在\(\tilde{\mathcal{G}_\mathcal{T}}\)中选择的目标的集合直到第\(t\)次迭代。令\(F\)表示一个映射函数,从集合到一个实数增益值(越大越好)。对于\(\mathbf{x}^t\in \tilde{\mathcal{G}_\mathcal{T}}\),我们定义\(\Delta(\mathbf{x}^t|S_t)=F(S_t\cup \{\mathbf{x^t}\})-F(S_t)\)为\(F\)在\(S_t\)时给定\(\mathbf{x}^t\)的边际效益。
形式上,随着迭代循环中迭代次数的增加,如果边际增益单调减少,那么f将属于子模函数族。对于子模函数问题,用贪心算法可以求得近似解。但本问题不是严格的子模函数,不过之前的研究表明问题不大。于是本问题也使用了贪心插入的策略。
我们采用贪婪插入算法进行近似子模优化,该算法计算每个对象在每次迭代时从目标集中获得的收益,并根据定义将收益最大的对象集成到当前子集\(S_t\)中:
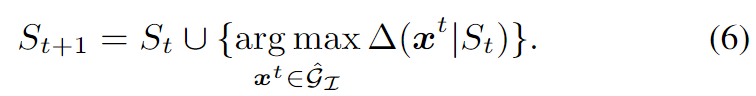
下面定义映射函数\(F\)。具体的,映射F定义为,先在之前用了\(S_t\)内的targets做了t次迭代的结果上进行一步迭代,得到被保护的图像\(\mathbf{x}^p\),再用\(G\)函数计算增益值。
合适的增益函数G应当选择最小化\(\mathcal{L}_{iden}(\mathbf{x}^t, \mathbf{x}^p)\)最有效的图像。要注意的是\(G\)必须是正值(为什么),并且越大代表效果越好。于是定义了一个基于特征相似度的增益函数:
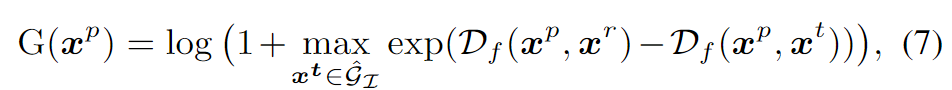
每次迭代时,算法倾向于选择一个在特征子空间里更接近真实图像的目标。
贪心插入算法流程如下:

中间迭代的时候只用\(\mathcal{L}_{iden}(\mathbf{x}^t, \mathbf{x}^p)\)做损失函数是因为,之前定义的损失需要一个batch进行计算,但是贪心插入的时候是针对一个图像的,没有batch。
5 Experiments
5.1 Experiments Settings
Datasets
在LFW和MegFace数据集上进行实验。为了接近真实的测试场景,我们涉及到一些额外的考虑因素。
- practical gallery set: 首先选择500个不同的身份做被保护的身份。同时随机对每个身份选择1张做probe image,并将同身份的其他图像在加入gallery set。
- target identities: 随机在MS-Celeb-!M数据集中选择10个身份作为\(\mathcal{T}\),每个身份选择一张图片形成\(\tilde{\mathcal{G}_\mathcal{T}}\),剩下的图像加入gallery set中,保证训练是的图像在gallery set中不可知。
- additional identities: 像gallery set中添加额外的500个身份,模拟真实的测试场景。
Target models
选择不同backbones和不同loss的模型。MTCNN用来检测人脸,并对齐为112x112的图像。只有一个模型被用于训练,剩下的作为黑盒模型。所用的模型如下表:

Compared Methods
许多之前的人脸加密动作都是single-target的。MIM将动量引入迭代过程,DIM和TIM通过输入多样化来增加迁移性。但注意TIM只专注于规避防御模型,并且在实验上也比MIM和DIM取得更差的性能。
由于原始DIM在迭代优化中只支持单目标攻击,因此我们在内部最小化中通过对同一目标集的动态赋值实现了DIM的多目标版本,命名为MT-DIM。
此外,我们还研究了其他多目标优化方法的影响。如将式子(7)改写为\(G_1(\mathbf{x})=log(1+\sum_{\mathbf{x}^t\in\tilde{\mathcal{G}_\mathcal{T}}}exp(\mathcal{D}_f(\mathbf{x}, \mathbf{x}^r)-\mathcal{D}_f(\mathbf{x}, \mathbf{x}^t)))\),这个方法命名为 Center-Opt. 这个方法使被保护图像向目标身份特征空间的中心更新。
MT-TIM, Center-Opt和本文的方法都是multi-target optimization methods,single-target methods之用一张图片做更新。
设置迭代次数为50, 学习率为1.5, 扰动大小最大为12在无穷范数下。
Evaluation Metrics
为了综合评估保护成功率,我们汇报Rank-N target identity success rate(Rank-N-T)和untarget identity success rate(Rank-N-UT)。
Rank-N-T表示在gallery set中与\(\mathbf{x}\)前N相似的,至少有1张属于target identity, Rank-N-UT表示前N相似的没有与\(\mathbf{x}\)相同身份的。
为了检验所生成的受保护图像的不可感知性,我们采用标准的量化指标峰值信噪比(PSNR )和结构相似度(SSIM),以及人脸区域的MMD。对于SSIM和PSNR,值越大表示图像质量越好,而MMD值越小表示性能越好。
5.2 Effectiveness of Black-box Face Encryption
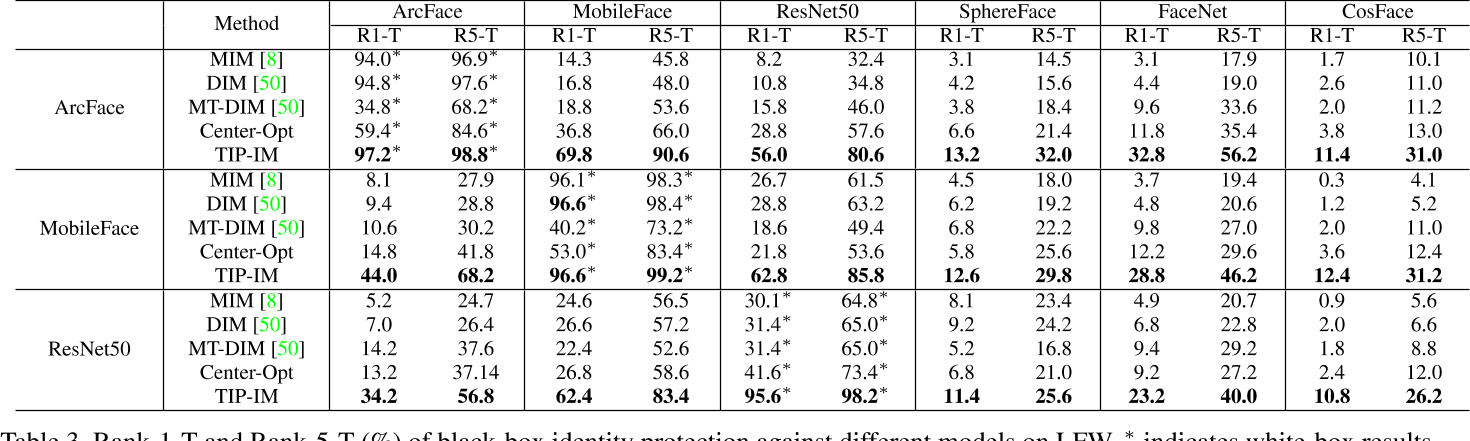

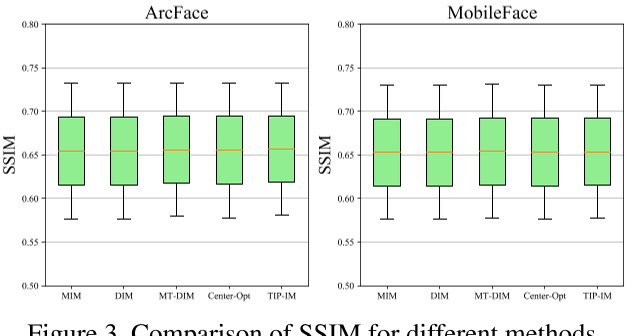
Tab.3 显示,在各种方法SSIM值很相近的情况下(Fig.3.),本文的方法在R-N-T的表现上比其他方法好很多。与singel-target方法DIM相比,MT-DIM获得了更好的性能,表明多目标设置可获得更好的黑箱迁移性。并且不同的multi-target方法表现也有差异,如本文提出的TIP-IM好于Center-Opt。
Tab.4 显示,本文的方法也能保证最佳的效果。
并且实验发现,10张target图片已经足够了,目标数量的小幅增加可以获得更好的性能,尽管需要略微的时间成本。
我们从StyleGAN中指定一些生成的图像作为目标图像。结果表明,该算法仍然具有良好的身份保护黑箱性能。在实际应用中,我们可以任意指定可用和授权的目标身份集或生成的人脸图像,我们的算法适用于任何目标集。
5.3 Naturalness
为验证本文方法能否控制自然度,对不同的系数\(\gamma\)进行枚举。Tab.5显示了不同的人脸识别模型(包括ArcFace、MobileFace和ResNet50)在PSNR、SSIM和MMD三个不同指标下的评价结果。随着γ的增加,生成的图像的视觉质量越来越好,这也与Fig4中的示例一致。因此,根据\(\gamma\)系数的不同,我们可以控制生成保护图像的自然程度。当\(\gamma\)增加时,图像看起来更自然,而在一定程度上,身份保护往往会失败。
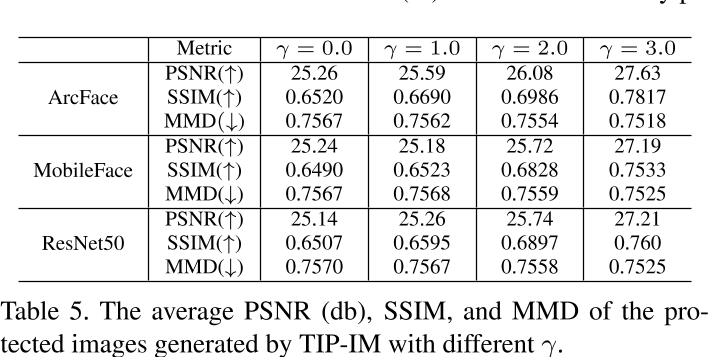

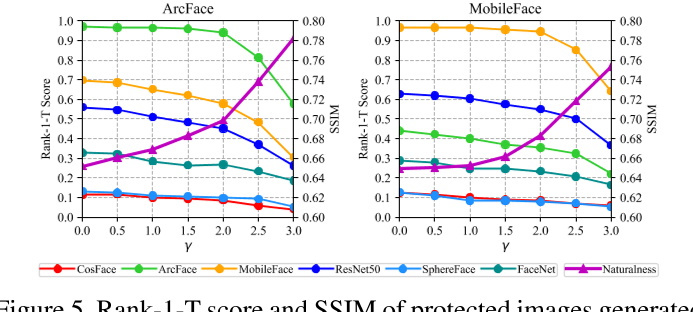
Fig.5 显示了不同的人脸识别模型(包括ArcFace、MobileFace和ResNet50)在PSNR、SSIM和MMD三个不同指标下的评价结果。随着\(\gamma\)的增加,SSIM值也在增加,Rank-1-T精度呈现下降趋势,这意味着适当的\(\gamma\)对可转移性和自然性至关重要。
5.4 Effectiveness on a Real-World Application
将提出的TIP-IM应用于腾讯AI开放平台提供的商业人脸搜索API上,测试身份保护性能。为了模拟隐私数据场景,我们使用上面描述的同一个图库集。在该平台中,我们从上述probe set中选择20个probe faces,基于相似度排序进行人脸搜索。所有20个probe faces都可以在Rank1被识别。然后从probe faces生成相应的受保护图像,进行人脸搜索。对于返回排名,有6个目标身份在排名1和16个目标身份在排名5。注意,具有相同身份的人脸相似度也呈现不同程度的下降,这也说明了黑箱人脸系统的有效性,如图6所示为两个示例。

6 Conclusion
在本文中,我们通过在社交媒体中模拟真实的身份识别系统来研究身份保护问题。大量实验表明,所提出的TIP-IM方法在不影响社交媒体用户体验的同时,能够保护用户的私人信息不被未经授权的身份识别系统暴露。
总结和思考
- 文章提出的multi-target方法,多一些target选择,可以显著增加迁移性和成功率,这对于人脸隐私保护来说,是很有用的。人脸隐私保护,只要认不出来就行了,可以使用de-identification,也可以使用target,而使用target方法,可以避免一些无辜的人身份被窃取。
- 文章提出的控制自然度,是用MMD放在损失函数中来实现的,用MMD来逼迫生成图像和原始图像分布相同。在读GAP文章的时候就在想有没有其他方法将生成图像控制在真实数据分布的流形上,GAP是用训练好的StyleGAN来隐式实现的,本文是用目标函数中加入正则化项来显式实现的。用MMD,但没有使用人脸的特殊性,如特殊特征什么的。
- 为什么Tab.4没有Center-Opt算法的数据了?
- 次模函数那块。前面的定义与submodular高度相似,submodular问题是NP-hard问题,但是可以用文中类似的贪心方法求近似解。(我觉得把本文中的F定义为次模函数有点牵强,毕竟每次更新所用的图像不一定是不同的。用其他近似方法求解可能会得到更好的效果)。用其他的方法,贪心的,亦或是其他启发式的算法,是不是可以提升性能呢。(而且计算增益的时候,是不考虑自然度的)
- 是否可以类似于OPOM,提供多张输入图片,来提升性能。
- 是否可以不人工指定target图像,而是根据什么准则、在什么条件下生成target?
其他参考资料
- MMD:https://zhuanlan.zhihu.com/p/163839117
- 定量评价图像生成质量:http://www.360doc.com/content/20/1127/03/72629698_948146939.shtml
- SSIM:https://blog.csdn.net/qq_42951560/article/details/115463083
- PSNR:https://blog.csdn.net/weixin_29732003/article/details/122569893