题目: OPOM: Customized Invisible Cloak towards Face Privacy Protection
作者: Yaoyao Zhong, Weihong Deng
链接: 文章链接
[TOC]
1 摘要翻译
人脸识别技术虽然在日常生活中很方便,但它可以在没有任何安全限制的情况下高效、隐蔽地分析人脸图像和视频,这也引起了社交媒体上普通用户的隐私担忧。在本文中,我们从技术的角度研究了人脸隐私保护,基于一种新型的定制隐身衣,它可以应用于普通用户的所有图像,以防止恶意的人脸识别系统发现他们的身份。具体地说,我们提出了一种名为“one person one mask”(OPOM)的新方法,该方法通过优化每个训练样本在远离源身份特征子空间的方向来生成针对个人(类)的通用掩码。为了充分利用有限的训练图像,我们研究了几种建模方法,包括仿射包、类中心和凸包,以更好地描述源身份的特征子空间。针对不同损失函数和网络结构的黑箱人脸识别模型,在普通数据集和名人数据集上评估了该方法的有效性。此外,我们还讨论了该方法的优点和潜在的问题。特别地,我们对视频数据集Sherlock的隐私保护进行了应用研究,以展示所提方法的潜在实际用途。
基本问题
- 论文解决的问题:生成针对个人的通用掩码来进行人脸隐私保护,这是一个新问题。
- 假设:通过更好地建模身份的特征子空间,可以提高Image Universality和Model Transferability。
2 Introduction
为保护隐私,一些研究旨在对人脸图像进行去识别 (de-identify),从而保留许多面部特征,但无法可靠地识别图像中的人的身份。考虑到生成的图像与原始图像可能具有不同的视觉外观,或表现不自然,出现不良伪影,一些最新的方法通过生成不易察觉的对抗样本作为掩码,既能隐藏识别信息,又能保持人脸图像的视觉质量。尽管这种方法生成的掩码很自然、很有效,但对于普通用户来说,为每张照片或每一帧视频生成不同的隐私掩码是非常不友好的。(现有方法不足)
为公众提供更有效、更简单的面部隐私保护,需要进一步研究。现有的方法针对一个人的不同面部图像生成不同的对抗mask,与之相比,我们的目标是生成一种针对个人的(类别)通用mask。通过这种方式,普通用户只用生成一次隐私保护mask,然后将其应用到他所有的照片和视频中。(针对现有方法不足提出的改进方向)
与image-specific的隐私面具相比,person-specific的通用mask有两方面的好处。首先,只生成一次针对个人的掩码,省去了生成新图像的掩码时间,在效率上有利于普通用户和一些实时隐私保护应用。其次,与image-specific掩码需要在用户和服务器之间多次传输新图像相比,person-specific的掩码只需要一次传输,可以降低隐私泄露的风险。(提出的改进方向的优点)
在生成针对个人的隐私掩码方面存在两个挑战。(1) Individual Universality。与image-specific的隐私掩码相比,person-specific的隐私掩码只需要用一个身份的少量图像生成,可以应用于不同的未知图像。而相同身份的面部图像可能因姿势、光照、表情和遮挡而不同。这种多样性无疑会增加为不同人脸图像生成隐私掩码的难度。因此,提高对抗型掩码的个体普适性对个人隐私保护至关重要。(2) Model Transferability 。隐私掩码需要在不同模型之间有迁移性。这意味着它们是由代理模型生成的,并应用于不同的未知识别系统。对于未知的人脸识别模型,有广泛的选择训练数据库,训练损失函数和网络架构。无疑会增加生产可迁移对抗掩码的难度。(提出新方向的挑战)
在本文中,我们提出了一种名为OPOM (one person one mask)的方法,为一个人的所有面部图像提供一个隐私掩码,类似于定制的隐身衣。具体而言,为了增加Individual Universality,OPOM通过解决优化问题生成隐私掩码,使训练图像的不同深度特征与身份特征子空间之间的距离最大化。我们研究了不同的建模方法,包括仿射包、类中心和凸包,以建模每个身份的特征子空间,以更好地描述有限的图像。我们通过实证发现,在掩码生成过程中,更好地描述特征子空间,可以提高个体的通用性和模型的可迁移性。此外,为了增加模型的可迁移性,OPOM还可以与多种模型可迁移性方法相结合,如动量法和DFANet。本文的主要贡献如下:
- 我们揭示了一种新型的person-specific(class-wise)通用对抗性隐私掩码的存在,它的生成是为了保护相同身份的不同人脸图像,因此可以更容易地为普通用户使用。
- 我们对这种新型的针对个人的隐私掩码进行了研究,提出了一种高效的对抗式掩码生成方法OPOM,该方法可以同时提高Image Universality和Model Transferability,从而实现更有效的隐私保护。
- 与以往的通用对抗扰动方法相比,本文提出的OPOM方法在不同的黑盒深度人脸识别模型下保护无约束人脸图像的有效性得到了实证验证。
3 Person-Specific Privacy Masks
3.1 Problem Formulation
person-specific对抗掩码的目标是去产生一个扰动\(\Delta X\),可以用于任何属于身份\(k\)的人脸图像\(X^k=\{X_1^k, X_2^k, \dots, X_i^k,\dots\}\)来欺骗各种深度人脸识别模型 \(f(·)\) ,就是寻找\(\Delta X\) 使得 \(X_i^k\in X^k\) \[ D(f(X_i^k+\Delta X), f_{X^k})>t, ||\Delta X||_\infty < \epsilon \,\,\,\,\,\,\,\,(1) \] 其中\(f(X_i^k)\in R^d\)是图像\(X_i^k\)的归一化特征,\(f_{X^k}\)表示身份\(k\)的特征子空间,\(t\)是决定两个图像是否是相同身份的阈值。\(D(x_1, x_2)\)是欧几里得距离或者余弦距离。\(\epsilon\)是控制扰动像素值的范围。
3.2 One person one mask (OPOM)
上式的关键点在于\(f_{X^k}\),但对于open-set人脸识别模型,被保护的人可能不在训练集中,就不能像以前的close-set任务的方法一样直接从模型中获取类别信息。因此,唯一的选择是从给定的人脸图像集\(X_k\)中描述身份\(f_{X^k}\)。目标是通过尽可能少的图像\(\tilde X_k=\{X_1^k, X_2^k, \dots, X_{n_k}^k\}\)来近似描述\(f_{X_k}\)
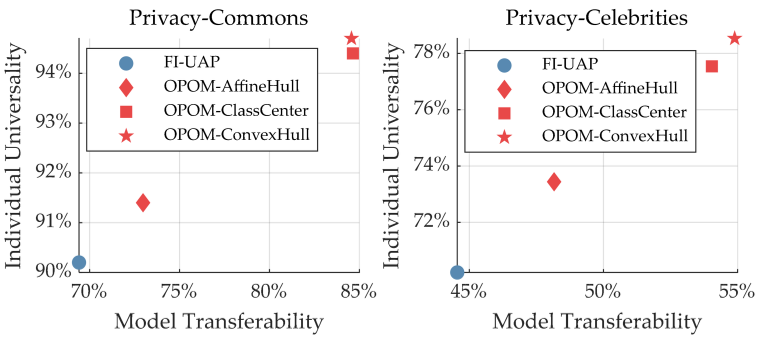
提出假设:有对特征子空间更精确的近似,Individual Universality可以提升;在近似表达式中有更多样的梯度信息,Model Transferability可以提升。
如图Figure2,用相同代理模型下不同图像的保护成功率来表示Individual Universality,用不同黑盒模型的平均保护成功率来表示Model Transferability, 实验表明假设成立。
3.2.1 Approximation methods of the feature subspace
3.2.1.1.Affine Hulls
使用图像集合中特征的仿射组合来表示特征子空间,即 \[ H(f_{\tilde X^k})=\{x=\sum_{i=1}^{n_k}\alpha_i^kf(X_i^k)|\sum_{i=1}^{n_k}\alpha_i^k=1\} \,\,\,\,\,\,\,(2) \] 于是可以优化以下式子来生成身份\(k\)的隐私掩码\(\Delta X\):
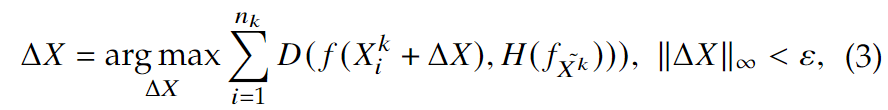
其中,\(n_k\)是图像数量,\(H(f_{\tilde X^k})\)是归一化特征的仿射包。
为计算\(D(f(X_i^k+\Delta X), H(f_{\tilde X^k}))\),可以把\(H(f_{\tilde X^k})\)写成以下形式来参数化仿射包:
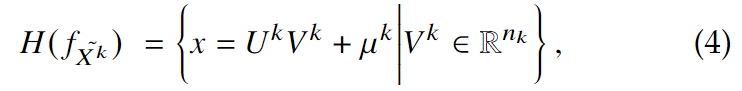
其中, \(\mu ^k=\frac{1}{n_k}\sum_{i=1}^{n_k}f(X_i^k)\), \(U^k\in R^{d\times n_k}\) 是张成仿射包的正交基,用\([f(X_1^k)-\mu^k,\dots, f(X_{n_k}^k)-\mu^k]\)做SVD求得, \(V^k\in R^{n_k}\)是自由参数的向量,即正交基各方向的坐标。于是\(D(f(X_i^k+\Delta X), H(f_{\tilde X^k}))\)可以写成:
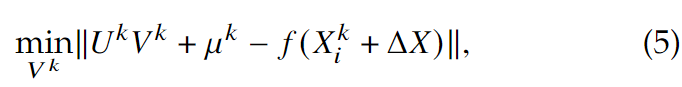
这个可以被写为标准的最小二乘问题:
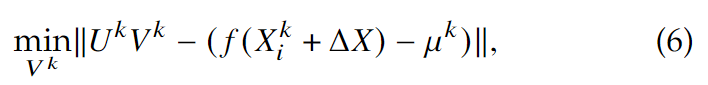
这个问题的解为,
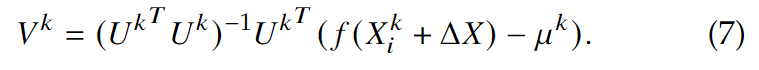
最后,生成隐私掩码\(\Delta X\)就把以上(3)公式变为:
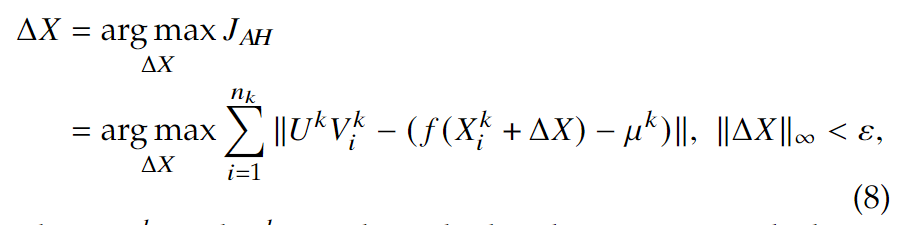
3.2.1.2 Class Centers and Convex Hulls
以上的仿射包对特征子空间进行的估计可能太过于松,因为仿射包上的许多点都没有用,甚至可能有副作用。于是我们引入了\(a_i^k\)系数的最低值和最高值,来控制松弛度:
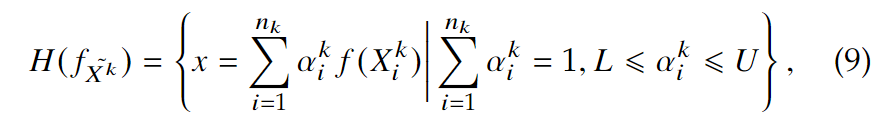
如果 \(L=-\infty, U=\infty\),则变成了仿射包。其他情况下,将会缩减过大的空间。当\(L=U=1/n_k\)时,身份特征就是\(H(f_{\tilde {X^k}})=\frac{1}{n_k}\sum_{i=1}^{n_k}f(X_i^k)\),即类中心。在这个设定下,隐私掩码的生成可以表示为:
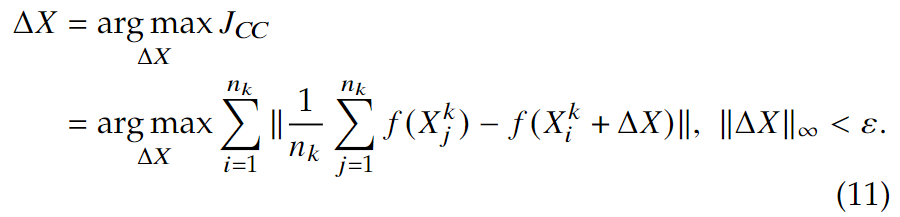
如果\(L=0, U=1\),则\(H(f_{\tilde{X^k}})\)就是特征\(f(X_i^k)\)的凸包,这也是实验表明最有效的估计。在这个设定下,计算\(D(f(X_i^k+\Delta X), H(f_{\tilde X^k}))\)就是一个有方形约束的最小二乘问题:
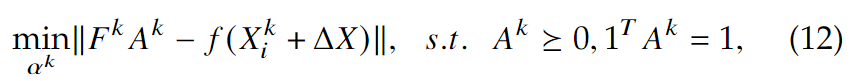
其中,\(F^k\in R^{d\times n_k}\)是一个列是\(f(X_i^k)\)的矩阵,\(A_k\in R^{n_k}\)是包含对应系数(\(a_i^k\))的向量。于是隐私掩码\(\Delta X\)的生成可以表示为:
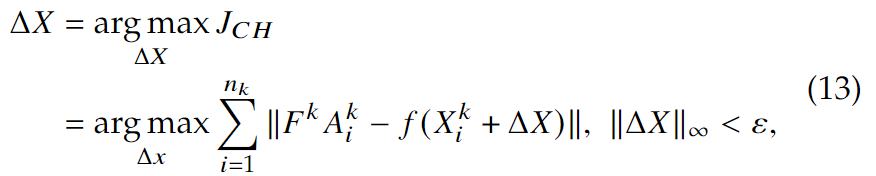
其中\(A_i^k\)可以由公式(12)求得。
3.2.2 Generation of Privacy Masks


坐标\(V_i^k\)和系数\(A_i^k\)要在每次迭代开始的时候计算。\(V_i^k\)有closed-form solution,\(A_i^k\)没有closed-form solution,但可以通过凸优化工具箱CVX高效求解。
3.2.3 Combination with Model Transferability Methods
与MI和DFANet结合。
3.3 Comparison methods
GD-UAP.
FI-UAP.
用UAP的方法与FIM结合。UAP的方法是使用一些图像用DeepFool迭代去求最小扰动,并将它们聚合为通用扰动。我们将\(\tilde X_k=\{X_1^k, X_2^k, \dots, X_{n_k}^k\}\)的梯度聚合去生成person-specific的掩码:
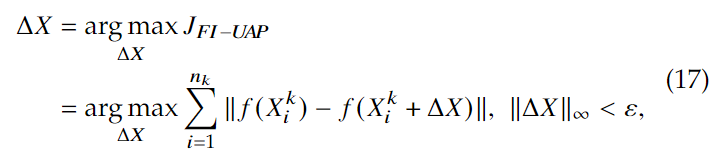
可以被看做式子(13)的特殊情况,即对角线只有对应位置为1,其余都是0。
FI-UAP+.
FI-UAP也可以使用类内交互来加强,即:
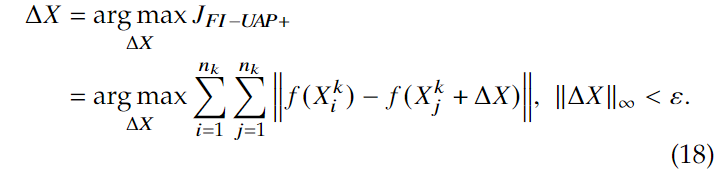
可以看做是OPOM-ClassCenter类似方法。
FI-UAP-all.
使用所有的训练图像去做FI-UAP.
GAP.
用生成式方法,根据原论文使用ResNet做generator,使用Feature-level loss.
4 Experiments
实验包括:对OPOM保护性能的评估,OPOM与其他可迁移方法的结合性能,对商业API的性能。最后提出了person-specific隐私掩码的优缺点,OPOM在视频隐私保护中的作用和为应对潜在的隐私掩码泄露的掩码多样性。
4.1 实验设置
使用正常人和名人两个数据集,使用1:N识别表现来衡量隐私保护率。每个人用M张图片进行测试,测试的时候每次选择1张图片放到gallery set中,用剩下M-1张图片加上隐私掩码做probe。使用Top-1和Top-5保护成功率来进行评价。
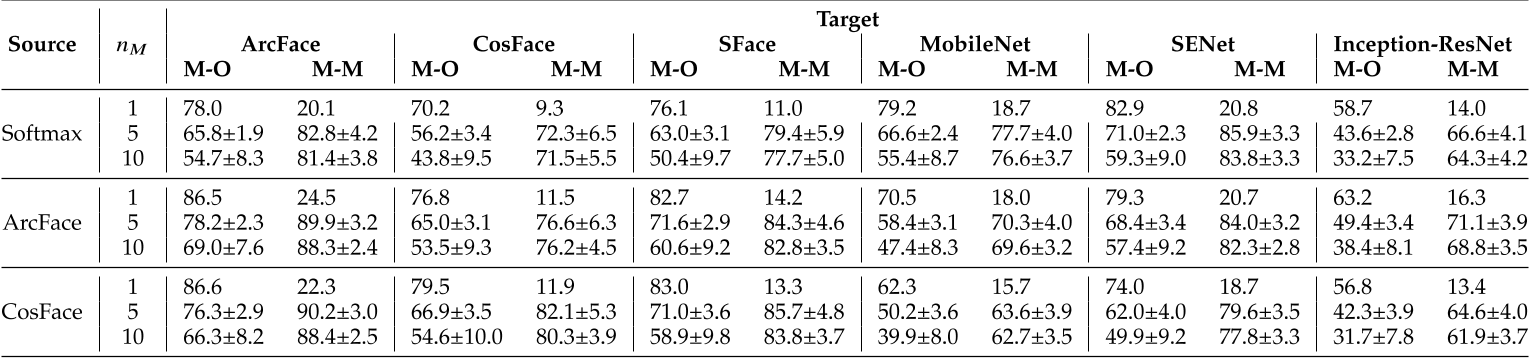
代理模型使用在在CAISA-WebFace数据集上训练的Resnet50,分别用 Softmax loss, CosFace, ArcFace监督。使用六个黑盒模型,其中三个损失函数不同,分别用CosFace, ArcFace, SFace;另外三个模型架构不同,分别用SENet, MobileNet, Inception-ResNet.
4.2 实验结果
4.2.1 OPOM保护效果
在常人数据集合名人数据集的测试结果。
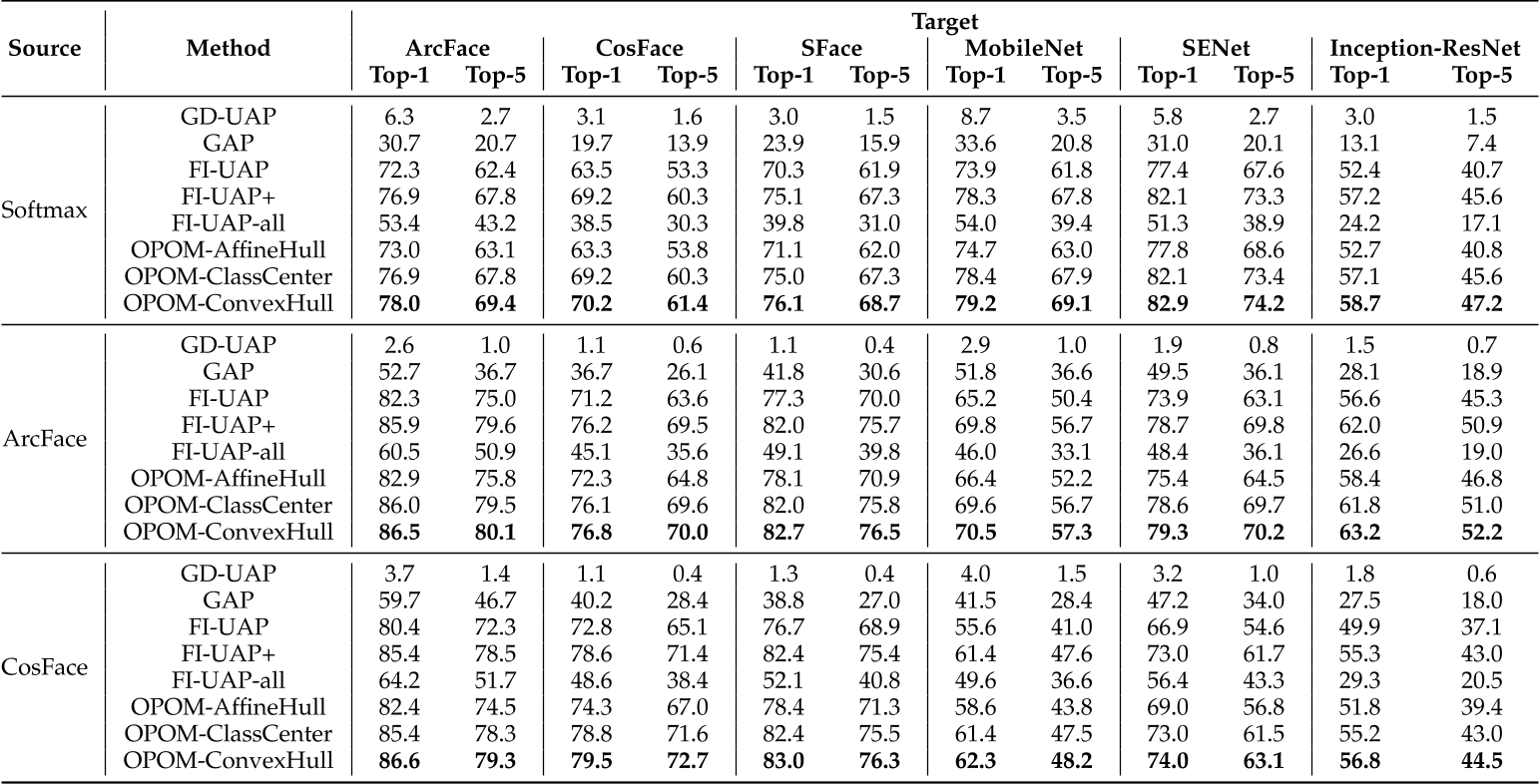
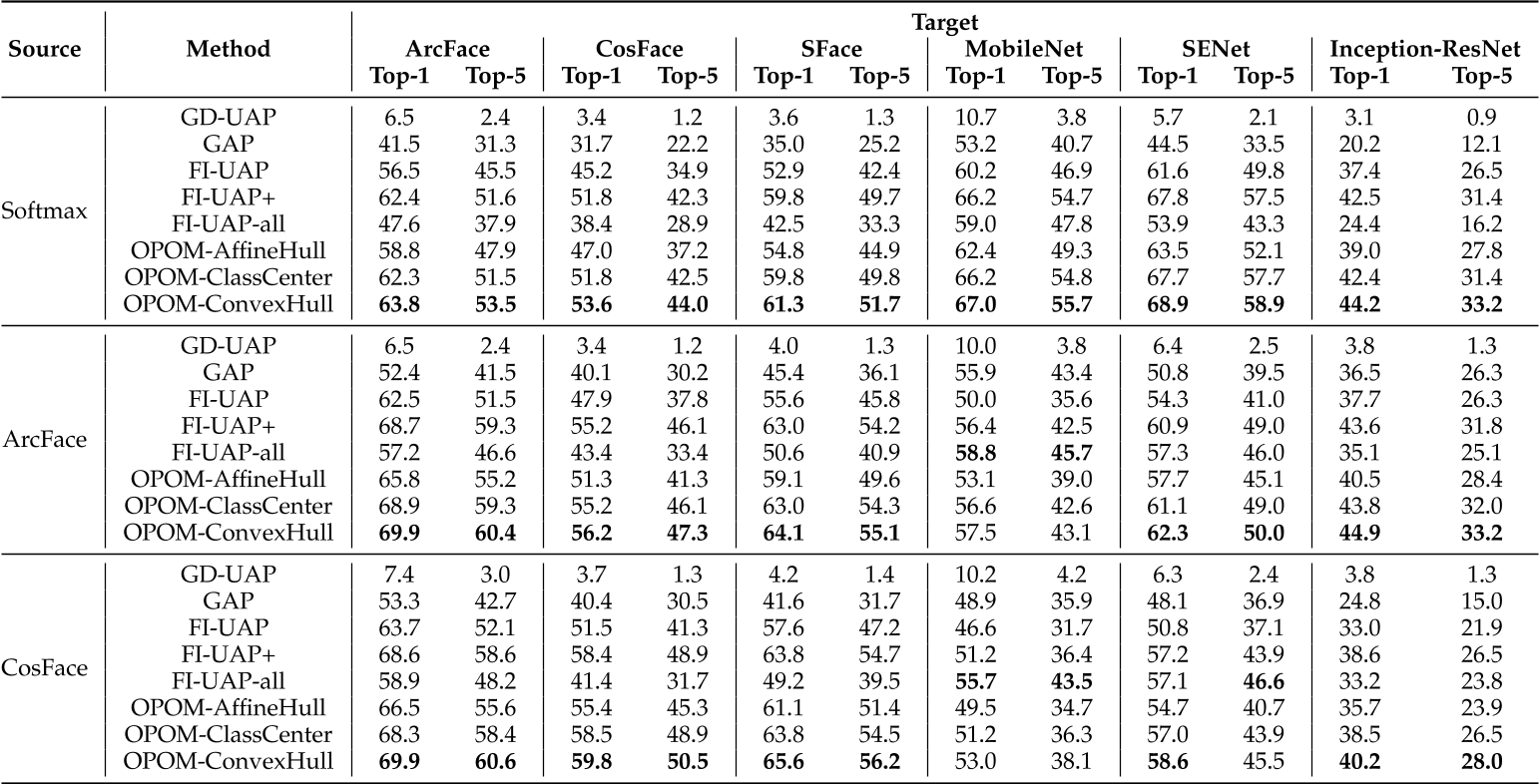
可以发现,描述特征子空间的近似方法对个体隐私保护任务有影响。
FI-UAP只使用单个特征,不能使用其他图像的特征。OPOM-AffineHull增加了特征空间,但是过于宽松。OPOM-ClassCenter与FI-UAP+很类似,但它可能忽略不同训练点\(f(X_i^k+\Delta X)\)的差别。OPOM-ConvexHull增加了特征空间到合适的程度,对于不同的训练点\(f(X_i^k+\Delta X)\)使用不同的支撑点,更有效地适应不同人脸图像。
4.2.2 与可迁移性方法的组合
这两张表表示在常人和名人数据集上,与可迁移性方法结合的保护效果的提升。
![TABLE 4 Comparison of different methods combined with the momentum boosting method [32] and DFANet [34] to generate more transferable person-specific privacy masks (𝜀 = 8) from a single source model to protect face images against black-box models. We report Top-1 and Top-5 protection success rate (%) under 1:N identification setting of the Privacy-Commons dataset. The increment compared with TABLE 2 is indicated by symbol ↑.](https://s2.loli.net/2022/08/05/RdB51JIDKzNotUh.png)
![TABLE 5 Comparison of different methods combined with the momentum boosting method [32] and DFANet [34] to generate more transferable person-specific privacy masks (𝜀 = 8) from a single source model to protect face images against black-box models. We report Top-1 and Top-5 protection success rate (%) under 1:N identification setting of the Privacy-Celebrities dataset. The increment compared with TABLE 3 is indicated by symbol ↑.](https://s2.loli.net/2022/08/05/e2pc9RjXKNLwISz.png)
随着使用动量法和DFANet,保护成功率进一步提高,但仍有提升空间。
4.2.3 在商业API上的保护
![Fig. 4. Protection against Commercial APIs (Amazon [62], Microsoft [63], Baidu [64] and Face++ [65]). Fifty identities in the PrivacyCommons dataset, each with 5 test images are used for the face verification test. The normalized average similarity/confidence scores are shown (lower is better). The original scores are listed above the bar.](https://s2.loli.net/2022/08/05/NnTrP5Lb68DOGya.png)
可以发现,由于商业的算法训练数据比较大,单纯用CASIA-WebFace数据集训练的代理模型表现并不好,在用更多数据集进行训练后,发现保护效果大大提升。
4.3 Discussion
4.3.1 Failure Case Analysis
文章给出了较容易失败的案例,每一行是一个人,左边是训练数据,中间是容易成功的图像,右边是容易失败的图像。生成的掩码在一定程度上可以泛化到其他图像上,但是如果测试图像和训练图像有显著差异,包括较大的姿势不同、光照和遮挡等,则容易失败。

4.3.2 Why person-spercific? Effectiveness and Efficiency
文章分析了person-specific, image-specific和universal mask的效果和效率。
Person-specific: FI-UAP, OPOMAffineHull and OPOM-ConvexHull.
Universal: GD-UAP, GAP and FIUAP-all.
Image-specific: FIM, LowKey and M-DI2-APF
用六个黑盒模型的平均保护率来表示效果,用Resnet-50生成100张图片的平均时间表示效率:
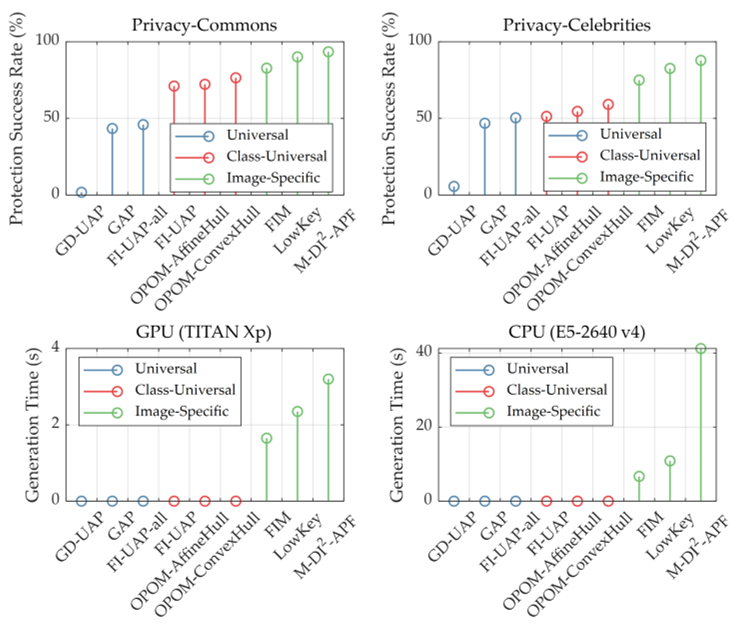
相比于Image-specific和Universal Mask,Person-specific在效率和效果上进行了tradeoff,更有利于普通用户和实时视频应用程序使用。
4.3.3 Privacy Protection in Videos
在《神探夏洛克》上抽取一些帧进行实验,用在6个黑盒模型上的余弦面部相似度的平均值和标准差来证明OPOM有效性。没有隐私掩码很容易识别角色,有隐私掩码可免于被识别。并发现使用15张图片进行训练,保护效果最好。
![Fig. 8. Application of OPOM in video privacy protection, Sherlock [66]. The privacy masks are trained with other face images of actors (Benedict Cumberbatch and Martin Freeman). The average cosine similarity between the deep features of the detected face in the video and the deep features of the corresponding characters (Sherlock Holmes and Doctor John Watson) is used to demonstrate the effectiveness.](https://s2.loli.net/2022/08/05/qmjBXga1vwRIGCp.png)
4.3.4 Diversity of Privacy Masks
如果存在信息泄露,则设计的隐私掩码有可能失效,于是本文设计了多个隐私掩码,向不同的方向进行优化。
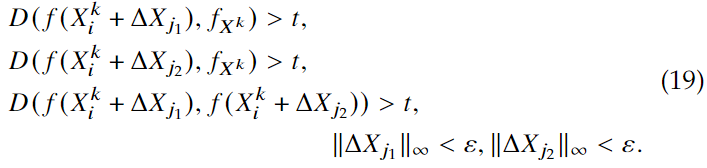
即保证隐私保护效果,也让不同掩码之间的距离足够大。
在实验中,也考虑到不同的被掩码保护的图像放在gallery set中,但文章没有给出具体细节。
 实验结果表明,person-specific的隐私掩码可以是多样的,但随着隐私掩码数量增多,保护率会下降。
实验结果表明,person-specific的隐私掩码可以是多样的,但随着隐私掩码数量增多,保护率会下降。
5. Conclusion
本文提出了一种class-wise的通用对抗扰动进行隐私保护的方法,通过生成一个可用于一个人所有图像的person-specific掩码。实验结果表明了该方法在定制化隐私保护任务中的有效性和优越性。我们已经证明了所提出的方法可以用于视频的隐私保护。已经取得了巨大的进展,但仍有许多工作要做。正如之前所说的,如果测试图像和训练样本之间存在明显的差异,那么提供保护是具有挑战性的。因此,需要进一步提高Individual Universality,以覆盖人脸图像潜在的多种变换,如较大姿态不同、不同光照和遮挡。如前所述,我们考虑了多掩码来解决隐私掩码泄漏的潜在问题。然而,所提出的方法在隐私掩码的多样性和效果方面存在挑战,因此仍是一个初步的探索。此外,我们目前正处于生成只能用于社交媒体上的数字图像和视频的数字隐身衣的实施阶段。如果它们能应用于现实世界的视频监控,将会产生更大的影响。
总结
提出person-specific隐私掩码的新方向,有很大的启发意义,后续研究空间也很大。
提出的估计特征子空间的方法用到凸优化一些定义,很有趣,但估计特征子空间的方法只有ConvexHull比FI-UAP+(ClassCenter)效果好,提升也不是很大,有较大的改进空间。
但有趣的一点是,在与迁移性方法结合后,各方法性能提升都很多,但AffineHull, ClassCenter和ConvexHull效果十分相近,文章并没有分析并给出解释。这么看起来就有了疑问,提出的估计特征子空间的方法得到的性能提升,到底是因为估计得更精准而提高了Individual Universality,还是在另一个方向上提高了Model Transferability? 我觉得应该补充实验,在白盒的设定下评估Individual Universality。(更正:可能有白盒设定,但文章里写得也不清晰。如果确实有白盒的话,则确实能表示提出的方法在估计特征子空间提高Individual Universality的有效性,但为何与迁移性方法结合之后就抹平了差距?)
在商业API的实验中,生成的掩码的保护效果与代理模型关系很大,用大量数据训练的代理模型与商业黑盒模型的gap可能更小,得到的掩码保护效果更好(其实还是Model Transferability的问题)。
不足
- 在处理训练图像与测试图像gap较大场景时效果很差,Individual Universality的问题,需要更好的估计特征子空间的方法。
- 在代理模型和黑盒模型训练数据有较大差距的时候,即代理模型与黑盒模型gap很大,则生成的掩码效果差,是Model Transferability的问题,需要更好的方法来提高迁移性。
- 隐私掩码多样性也需要探索,直接生成相距较远的多个隐私掩码,得到的保护率会下降。
- 现实世界的应用,较为困难。