题目: Improving Transferability of Adversarial Patches on Face Recognition with Generative Models
作者: Zihao Xiao, ..., Jun Zhu
会议:CVPR2021
链接:文章链接
摘要翻译
深度卷积神经网络大大提升了人脸识别性能。最近,人脸识别模型已经被用于安全敏感应用的身份认证。然而,深度CNN对于对抗补丁来说很脆弱,这些对抗补丁可以在现实中实现并且隐蔽,这对这些模型在现实世界中的应用提出的新的安全问题。
在本文中,我们使用基于可迁移的对抗补丁来评估人脸识别模型的鲁棒性,其中攻击者对目标模型的可访问性有限。
首先,我们对现有的基于迁移的攻击方法进行扩展,生成可迁移的对抗补丁。然而,我们发现迁移性对初始化很敏感,当扰动较大时迁移性下降,表明对替代模型过拟合。
其次,我们提出了在低维数据流形上对对抗补丁进行正则化。这个流形有在合法人脸图像上预训练的生成模型表示。将像人脸的特征(face-like feature)作为对抗扰动,通过在流形上的优化,我们表明替代模型和目标模型之间的响应差距显著减小,并且表现出更好的迁移性。
大量的数字世界实验证明了该方法在黑箱设定下的优越性。我们也将提出的方法应用于物理世界中。
基本问题
论文解决的问题:提升人脸识别中对抗补丁的迁移性
动机:
先前的对抗补丁的工作基于白盒设定,或者基于询问的设定,但部署在现实世界中的模型不能轻易被访问。所以本文聚焦于提升query-free black-box setting的迁移性。在这个设定下,基于迁移的对抗攻击被广泛使用。
现有的提升对抗样本迁移性的方法聚焦于使用先进的非凸优化、数据增强等方法,这些方法通常是为了生成\(L_p\)约束的对抗样本,我们发现这些方法也提升对抗补丁的迁移性,但我们发现这样也容易陷入局部最优,迁移性不令人满意的。首先,迁移性对算法的初始化很敏感。其次,随着扰动强度增加,迁移性先上升后下降,有过拟合现象。所以需要新的正则化方法以减轻对代理模型的过拟合。
相关工作
- 对抗补丁。先前工作都是基于白盒设定的。
- 可迁移的对抗样本。大多数是用在生成\(L_p\)约束下的对抗样本,但可以被迁移至对抗补丁中。但易陷入局部最优。
- 对抗样本的生成式模型。现有的生成式方法迁移性有限,如SemanticAdv。
科学假设:不同的人脸识别模型对类人脸特征(face-like features)的响应是有效相关的,这可以提高对抗补丁的迁移性。
贡献:提出通过在低维流形上对对抗补丁进行优化来进行正则化,流形用生成模型表示,在其latent space内进行优化。
方法
TAP-TIDIM
即用momentum、diversity input、transform方法生成可迁移对抗补丁,很简单。

但容易过拟合,
迁移性对初值很敏感。对于目标攻击,仅把初始值换成目标人脸,就有很大的迁移性提升。
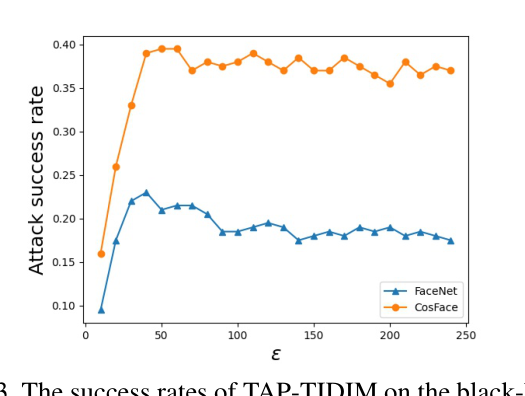
当搜索空间变大时,迁移性降低。对于\(L_\infin\)约束,当可改变像素值越大时,性能先提升后下降,这是过拟合的体现。
Generative adversarial patch
提出在低维流形上对对抗补丁进行正则化优化,以避免优化问题中迁移性不佳的局部最优情况。
这个流形需要具备的性质:
- 足够的能力。即可以成功攻击白盒代理模型。
- 良好的正则化。即使代理模型和目标模型的响应是相关的,以减轻过拟合。
文章使用了一个生成模型学习到的流形,这个生成模型是在正常人脸图像上训练的。使用\(h(S):S\to R^n\) 表示这个生成模型,\(S\)表示latent space。之后就是对某一个latent code进行优化,文章中用的Adam。
优化问题就变为:
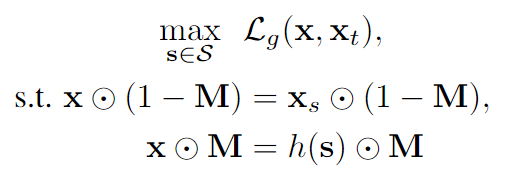
实验
实验设定
数据集:LFW和Celeb_HQ。对于face verification,选择400对不同身份的人脸图像。对于face identification,选择400个图像作为gallery set,选择与之前400对应相同身份的400张图片作为probe set。
人脸识别模型:FaceNet, CosFace, ArcFace,在LFW数据集上达到了99%正确率。每个模型的cosine相似度阈值都是通过在6000对(3000对相同身份、3000对不同身份)图像上测试的最好阈值。同时用了Face++和Aliyun的模型。
生成模型:ProGAN, StyleGAN, StyleGAN2
补丁位置:眼镜和口罩....
度量准则:对于face verification使用阈值,对face identification使用最近邻。用成功率衡量。
实验结果
在dodging和impersonation设定下分别进行实验
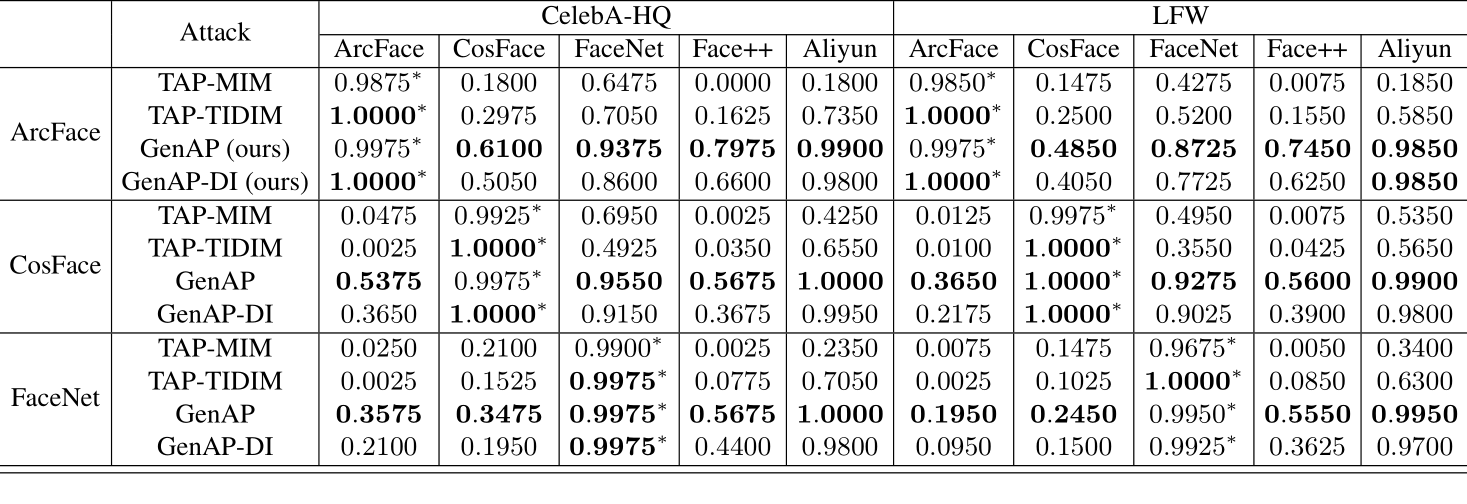
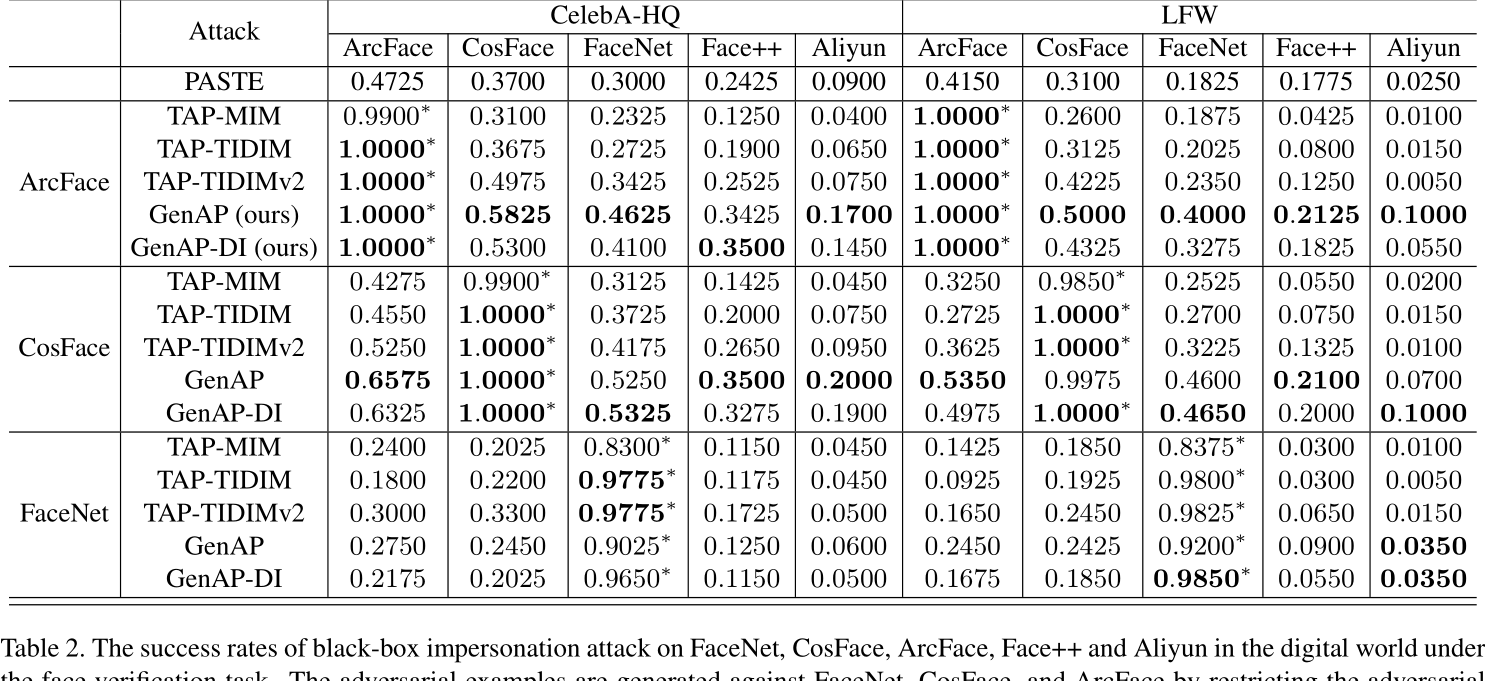
- TAP-TIDIM表现好于TAP-MIM。表明先前提高迁移性的方法在对抗补丁上仍然有用。
- 单纯的GenAP在大多数情况下好于TAP方法,证明提出的正则化方法的有效性。
- GenAP和GenAP-DI表现相似,在本方法上增加di没用。
- GenAP比简单的PASTE效果好很多,表明GenAP不仅在生成目标人脸的特征,也在寻找适合攻击者面部特征的对抗性特征。
- 商业模型Face++和Aliyun对对抗补丁的脆弱性。
Ablation study on GenAP
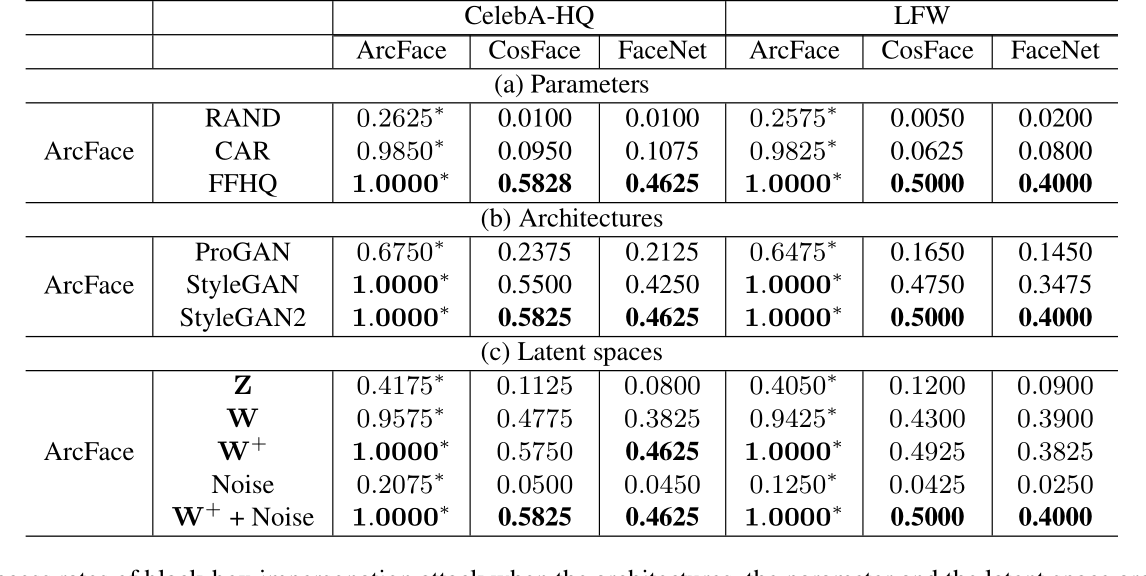
生成器模型的参数
使用StyleGAN2,改变参数进行实验。分别是随机、在car数据集上训练、在人脸数据集上训练。
使用\(W^+\)和Noise作为latent space。
Table3(a)说明,在CAR数据集上训练的模型白盒攻击表现较好,但是基本没有迁移性;在人脸数据集上训练迁移性好很多。表明使用face-like特征作为扰动, is important for bridging the gap between the substitute and the target face recognition models to improve transferability in the GenAP methods.
生成器模型架构
Table3(b), StyleGAN2表现最好。
生成模型的latent space
Table3(c), \(W^+\)+ Noise 最好。
(这跟跟直觉很符合,靠近StyleGAN主干更利于编辑,更富于语义信息)
物理世界实验
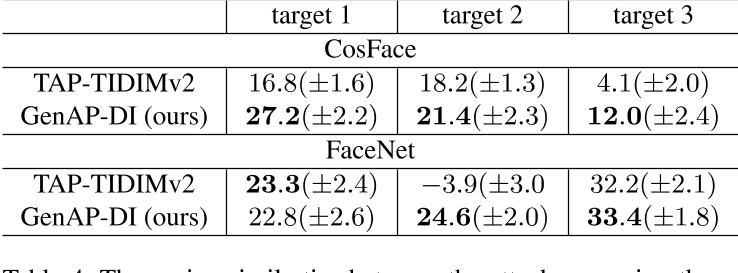
具体来说,从CelebA-HQ数据集中选择了一名志愿者作为攻击者和3个目标身份(一男两女)。对于每个目标身份,我们为攻击者生成一个眼镜框来模拟该身份。攻击者戴上对抗性镜框后,我们从正面拍摄他的视频,随机选取100帧视频。视频帧用于人脸验证。我们使用余弦相似度来评估补丁的可转移性。相似度越高,可转移性越好。从图4的结果可以看出,本文所提出的GenAP-DI生成的patch在打印和拍照后仍然保持较高的可转移性。
其他实验
说明了SemanticAdv方法的次优,并将本方法拓展到其他任务。
待填!!!!!!!!!!!!!!
结论
本文研究了query-free black-box设定下人脸识别模型对对抗补丁的鲁棒性。首先,我们将现有的技术从\(l_p\)约束(p > 0)的设置扩展到patch的设定,生成可迁移的对抗patch的TAP算法。然而,一些实验现象表明,TAP算法很难摆脱局部最优,迁移性性不理想。因此,我们提出在人脸图像上预先训练的生成模型学习的流形上对对抗补丁进行正则化。所提出的GenAP算法中的扰动类似于人脸特征,这对于减少替代模型与目标人脸识别模型之间的差距具有重要意义。实验验证了所提方法的优越性。
思考
问题:
- 使用StyleGAN模型有点庞大。
思考:
不同GAN模型之间的差距还是很大的,越有语义编辑特性的模型效果越好。并且对Z的优化竟然效果那么差....原因?
为什么之前的方法那么容易陷入局部最优。
新提出的正则方法就是将扰动局限在人脸特征中,并且还能在这个latent space中找到对抗样本,对GAN的要求有点高。
有没有别的方法可以达到类似的效果
发现这个方法有目标攻击生成的补丁和目标人的特征很相似,其实就相当于保留目标人脸的特征的前提下(本文提出的正则化),尽可能搜索对抗样本。有没有其他方法可以在修改的时候既保留人脸特征又有对抗性?

